Trial Similarity Search
Table of Contents
We implement trial search task that aims to find similar trials to a given trial. This function is rather useful when practioners are designing new trials. They can refer to the retrieved historical trials, which provide valueable information for the trial’s design, outcomes, and also look for potential collaborations. To be more specific, we concentrate on the dense retrieval where each trial document is encoded as a dense vector. Such that, trial similarity is measured through the cosine similarity between the trial vectors.
Formally, a trial document consists of multiple components, as 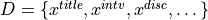 .
The target of dense retrieval is to convert the input document to a dense vector
.
The target of dense retrieval is to convert the input document to a dense vector 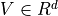 , such that we can
compute the trial’s similarities and identify similar trials.
, such that we can
compute the trial’s similarities and identify similar trials.
Trial Similarity Search: Index
Trial Similarity Search: Example
Here, we highlight the usage of trial_search.trial2vec model for this task. Other models have the similar pipeline.