Patient-Trial Matching
Table of Contents
The patient-trial matching is a process that identifies patients who are eligible to participate in a clinical trial. The matching process is based on the patient’s electronic healthcare records (EHRs) and the trial’s inclusion/exclusion criteria. To formulate it as a machine learning problem, we first need to define the input and output of the matching process.
A patient’s EHR can be represented by a sequence of visits 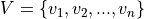 , where each visit
, where each visit
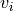 is a sequence of events
is a sequence of events 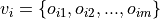 . We can encode
. We can encode 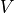 to a compact
embedding
to a compact
embedding 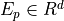 as the patient’s representation. The trial’s inclusion/exclusion criteria can be represented by a
sequence of inclusion/exclusion criteria
as the patient’s representation. The trial’s inclusion/exclusion criteria can be represented by a
sequence of inclusion/exclusion criteria 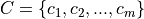 . We can encode
. We can encode 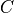 to a compact embedding
to a compact embedding
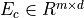 the trial’s representation (each criterion is a vector). Such that, the neural matching process
is just compute the similarity between
the trial’s representation (each criterion is a vector). Such that, the neural matching process
is just compute the similarity between 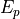 and
and 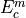 to get the criterion-level affinity.
to get the criterion-level affinity.
Patient-Trial Matching: Index
Here is the list of colab examples on each model for this task.
Patient-Trial Matching: Example
Here, we highlight the usage of trial_patient_match.deepenroll model for this task. Other models have the similar pipeline.